
The previous article [Introducing Artificial Intelligence (AI) in Companies] describes “AI has objectives depending on its scale”, “AI in companies is effective through orchestration using small language models” and “Information sources confidentiality also needs to be protected in AI”.
Additionally, it describes “In the case of Microsoft 365 data is information sources, the confidentiality is best on Microsoft 365 rather than moving to other storages” and “In the case of the information sources being non-Microsoft 365 data, Information sources should be stored in individual storages that match access permissions, and divided schemes of several AI on orchestration foundation when the identity federation is not complete”.
• In the case of the information sources being non-Microsoft 365 data and In the case of the identity federation is complete.
If the identity federation is aggregated to the Entra ID account, it is good that information sources are stored as Azure resources. Even if information sources are non-Microsoft 365 data, it is super easy to control access to information sources of AI.
Information sources can be prepared or real time. [Add your data] feature of Azure AI Studio supports various file types. Or using connector supports Azure AI Search, Azure Cosmos DB for MongoDB vCore, and URL/web address.
If information sources could not be stored as Azure resources, Entra ID that aggregated as the identity federation should control access to AI.
Azure provides various connection services such as provisioning or authorization delegation calls (if the service provider supports it) as the identity federation features.
Thus in the case of AI that uses information sources outside of Azure, it is good that information sources are designed as single access permission.
• Design steps for Introducing AI to companies
When introducing AI to the company, consideration of The state of the user account of the organization and the purpose of AI in the company is the first step of design.
It’s an important decision point whether the purpose of using AI in the company is to leverage Microsoft 365 data or not. Whether the user account of the organization has already completed the identity federation or not is also important because Microsoft 365 data is protected by the Microsoft 365 identity foundation. This official article provided by Microsoft describes that the identity foundation of Microsoft’s tremendous robustness and flexibility can address enterprise compliance and governance.
The next step is considering the need to customize for using the company’s data. Then programming or No/Low code development is necessary or not. These steps lead to how to implement AI in the company.
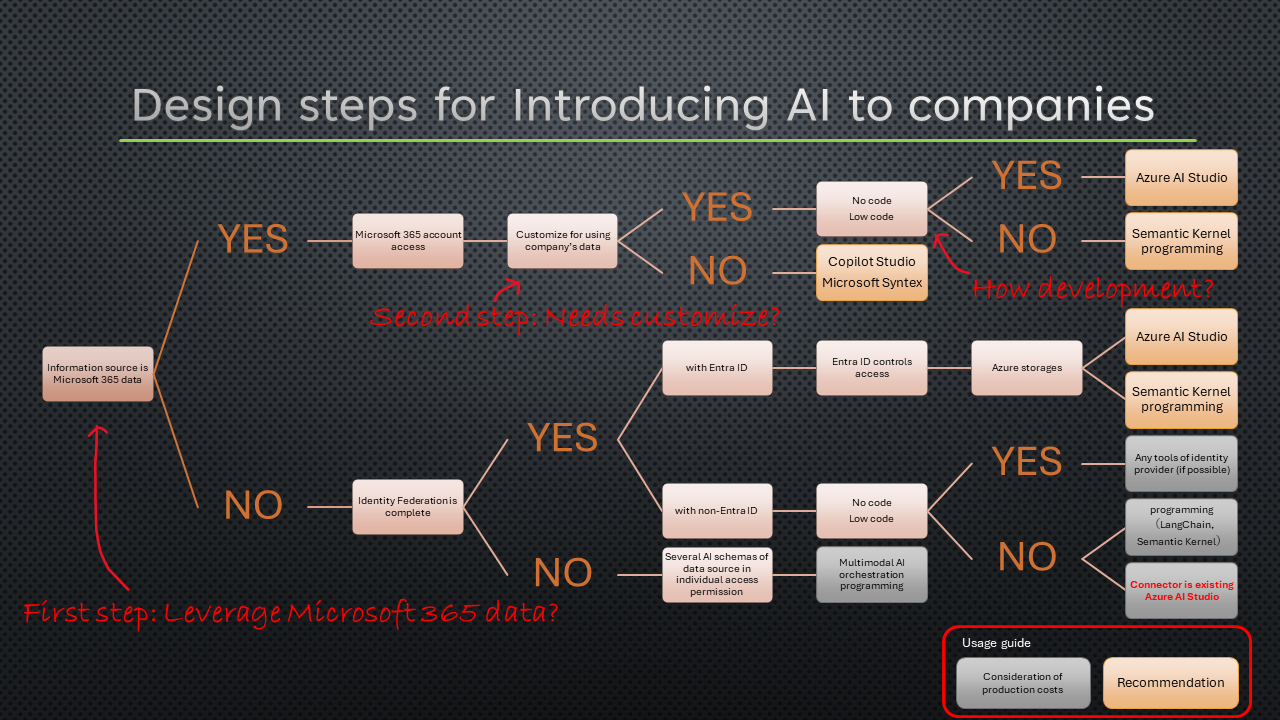
Most easiest way to introduce AI to the company is Microsoft 365 data leverage on the company. Microsoft Syntex stores metadata of files of SharePoint, it classifies files as various aspects and then shows them on the SharePoint site. Furthermore, generates documents with Power Automate. On creating UI, Copilot Studio also relays with Power Automate for using Microsoft 365 data and other data, creating cloud flow. These services will be described in my other articles.
It is complex in the case of the information sources being non-Microsoft 365 data.
One way to divide sources is an aspect of access permissions, it said above, and another way is to divide by use case that does not matter accessed identities.
It is important how data is divided by permission when information sources of AI such as access accounting data or human resource data although, it is not important to divide data with identity to access IoT data unmanaged by id. These data might be divided into use cases for efficiency or agility.
Furthermore, it is important to consider whether the identity federation is complete or not. If the identity federation is complete with Entra ID and stores the whole of the data as Azure resources, it needs only implement the orchestration of AI.
So this article describes how to implement AI using Microsoft 365 data with additional data. My other articles describe content other than AI orchestration.
• Story of the sample of this article
As a sample of AI using Microsoft 365 data with additional data, design levels of accessing information sources of AI that is like the following figure.
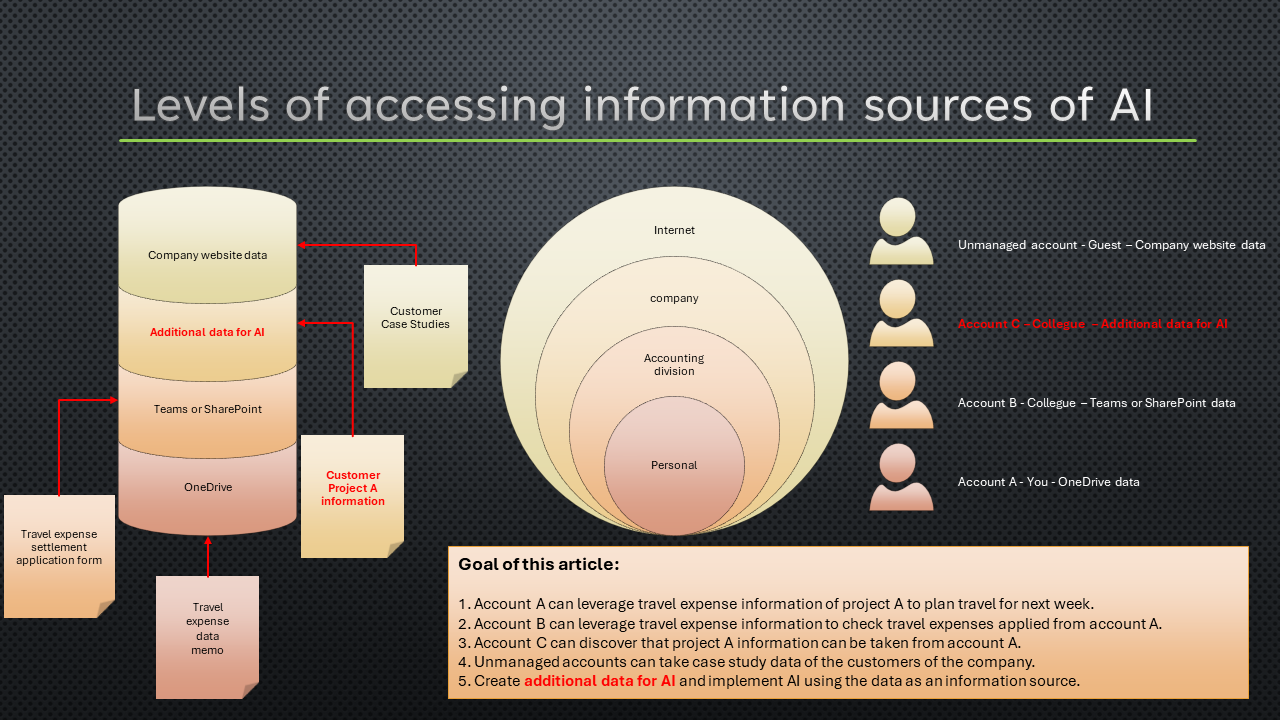
The additional data in the figure above is used in AI. For example, the travel expense data is shared only with the accounting division using SharePoint or Teams. Though the additional data is not shared with the company’s colleagues explicitly, It is better that colleagues who are not engaged accounting division can search related to the travel expense data such as heuristic knowledge that is assembled by the employee who applied travel expenses. This article creates the AI that orchestrates with Microsoft 365 using such data.
• Preparing a Small Language Model for the company’s data
There are several types of language models, types are such as foundation models, fine-tuned models, and quantization models. Now, the Trainer model such as Orca-2 exists and creates small language models, training, and creating datasets, for foundation models.
It is better to use fine-tuned models than foundation models because they are already fine-tuned using a dataset for specific tasks if the usage of the additional data of the company on AI matches the task of fine-tuning. Copilot for Microsoft 365, BloombergGPT, or Automatic-Speech Recognition of Alexa are representative.
Additionally, if GPTQ (Quantization for Generative Pre-trained Transformers) for fine-tuned models exists, it is better to use quantization models than fine-tuned models because quantization models are model compression using the one-shot weight quantization method, it can be used without GPU. Thus, the search for a model that aligns with the task at Hugging Face, TensorFlow Hub, or PyTorch Zoo at first. This article uses Hugging Face because using a model launcher distributed on Hugging Face. Model launcher is easy to search by typing “Ollama” at Hugging Face, Ollama is similar to LlamaIndex, LangChain, Semantic Kernel, Rust LLM, and Roboflow, they support many models.
Ollama also has an eco-system as Ollama’s official image at the docker hub or can be installed on Linux using WSL2 as well. Models that are not Quantarizationed can be compressed using a GGUF file.
There are libraries to create a pipeline for C#, so it’s easy to implement local AI as figure below using Ollama.
No responses yet